Introducing BarkMode: Bark Detection + Dark Mode

I was in California about a month ago for work and I was able to attend a few events during WWDC week. I read a lot about the new features and APIs but didn’t really have a lot of time to mess with stuff like SwiftUI, etc. I got a stupid idea for a project but I didn’t really take the time to work on it until this weekend. Now I’d like to introduce you to my latest app: Bark Mode!
WTF is Bark Mode?
Right after the new APIs were announced at WWDC, I scanned them for anything that might be interesting. I really like being one of the first to try out a new technology, but I figured that everyone would be all over SwiftUI, and I was right. I found a somewhat obscure new feature as part of CreateML that allowed users to generate a ML model that could classify sounds.
This SoundAnalysis API in particular seems relevant to my typically immature interests. 💨 #WWDC19 https://t.co/0Aipwa99Lu
— Hung Truong (@hungtruong) June 4, 2019
Of course the first thing I thought of was to make an app that could detect farts. I could even make it so that a fart would toggle dark mode off/on. Though I wanted to start experimenting right away, I discovered that you actually needed to have the newest version of macOS Catalina installed in addition to the newest Xcode to use Create ML, and I didn’t have my personal computer handy and couldn’t install a beta OS on my work computer, so I ended up not building it.
Fast forward to this weekend, and I eventually got Catalina and all the other prerequisites I needed to get started. Instead of “FarkMode” which doesn’t really make sense, I decided to switch it up this time and detect dogs barking, since “Bark” rhymes better with “Dark” than “Fart.” Plus everybody loves dogs! Perhaps I’m finally maturing in my old age (probably not).
Anyway, here’s the steps I needed to take to make my BarkMode app.
Creating the model
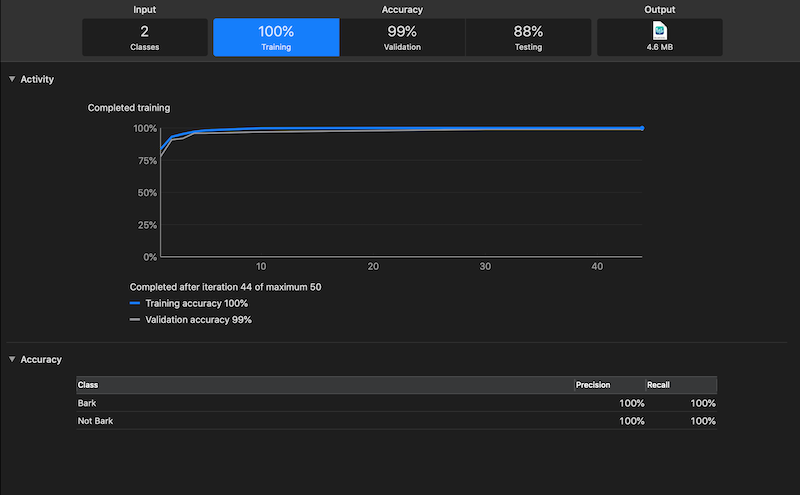
I had seen some videos of people making image classifiers using CreateML in the past. It seemed as easy as creating a few folders with different labels and images of those things. You would have to create one batch for training images, and another for optionally testing the models once they were created.
The process for creating an audio classifier is pretty similar except that you need to use sound files instead of images. I started by finding a bunch of stock sound effects of dogs barking. I also found a bunch of random stock sound effects of things like bells ringing, wind blowing, and other stuff that I could label as “not barking.” I feel like this is a pretty wacky way to do classification but if there’s another way that doesn’t involve downloading a bunch of random stock sound effects, that would be awesome.
At first I took larger sound files and chopped them up into really short ones. This way I had a bunch of training data that I can use both to train and test my classifier.
However, when I ran the Create ML app on the training data, I got an obscure error that the training had been interrupted. I saw that the app thought I only had 3 files when I had created a bunch more. I believe that Create ML is unable to train with really short audio files (less than a second). I ended up inserting the full sound files instead of the short ones. At this point I think I had about 8 or 9 files for either barking or not barking.
The model was created but it had a really terrible accuracy. I decided to just add a bunch more files both of dogs barking and things that weren’t dogs barking. The more examples I added the “better” the model became.
Polishing the model
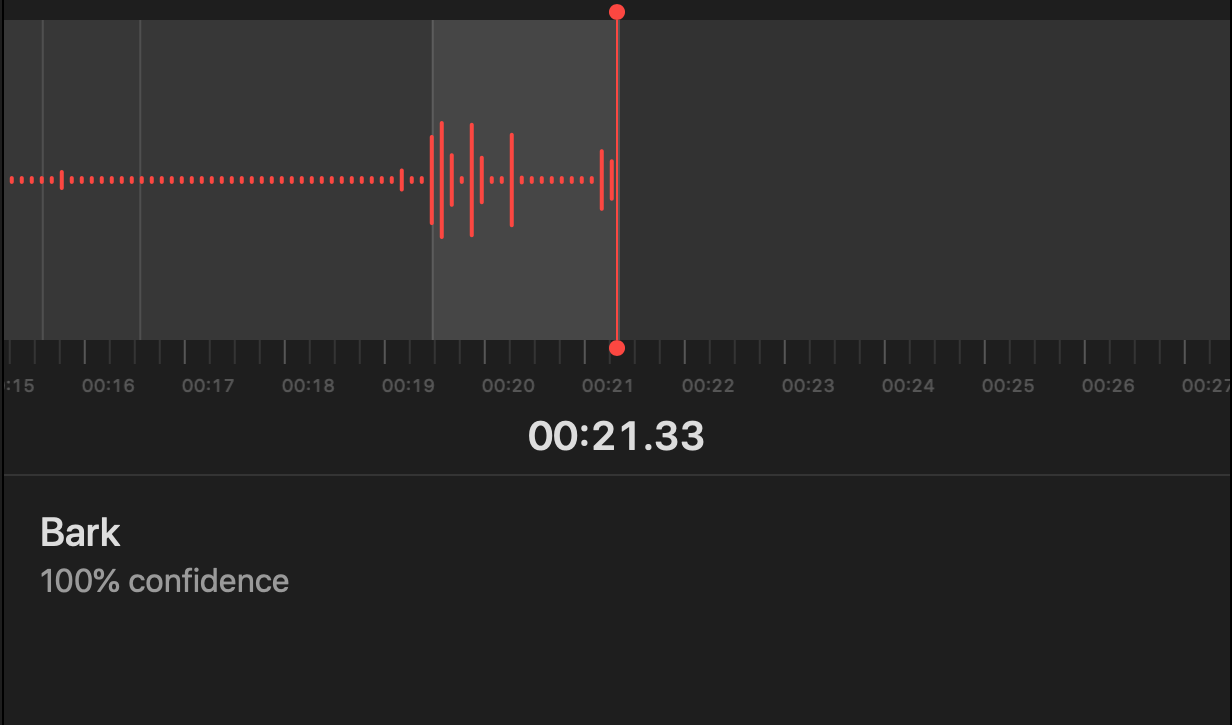
Create ML has a feature where you can test your audio classifier with audio data coming from your own microphone. When I did this I noticed that the model was too biased towards no sound being barking. I’m not sure why but maybe white noise sounds more like barking than an old timey car horn?
I ended up adding a bunch of white noise and recorded some nothing to add to the model. This helped quite a bit. The last thing I did was also record some audio of myself talking so that the model would not recognize me talking as barking. This was useful so I wouldn’t get false positives during my demo video (which I ended up getting anyway in a bunch of outtakes).
Integrating the model in the app
I created a new app and promptly enabled “Use SwiftUI.” Then I promptly made a new project because I couldn’t figure out where my ViewController class was! I’ll take a look at SwiftUI later but for now I’ll focus on getting my BarkMode app actually working.
The Create ML app made a model that I could then copy into my app. It was really as simple as dragging it from one place to another.
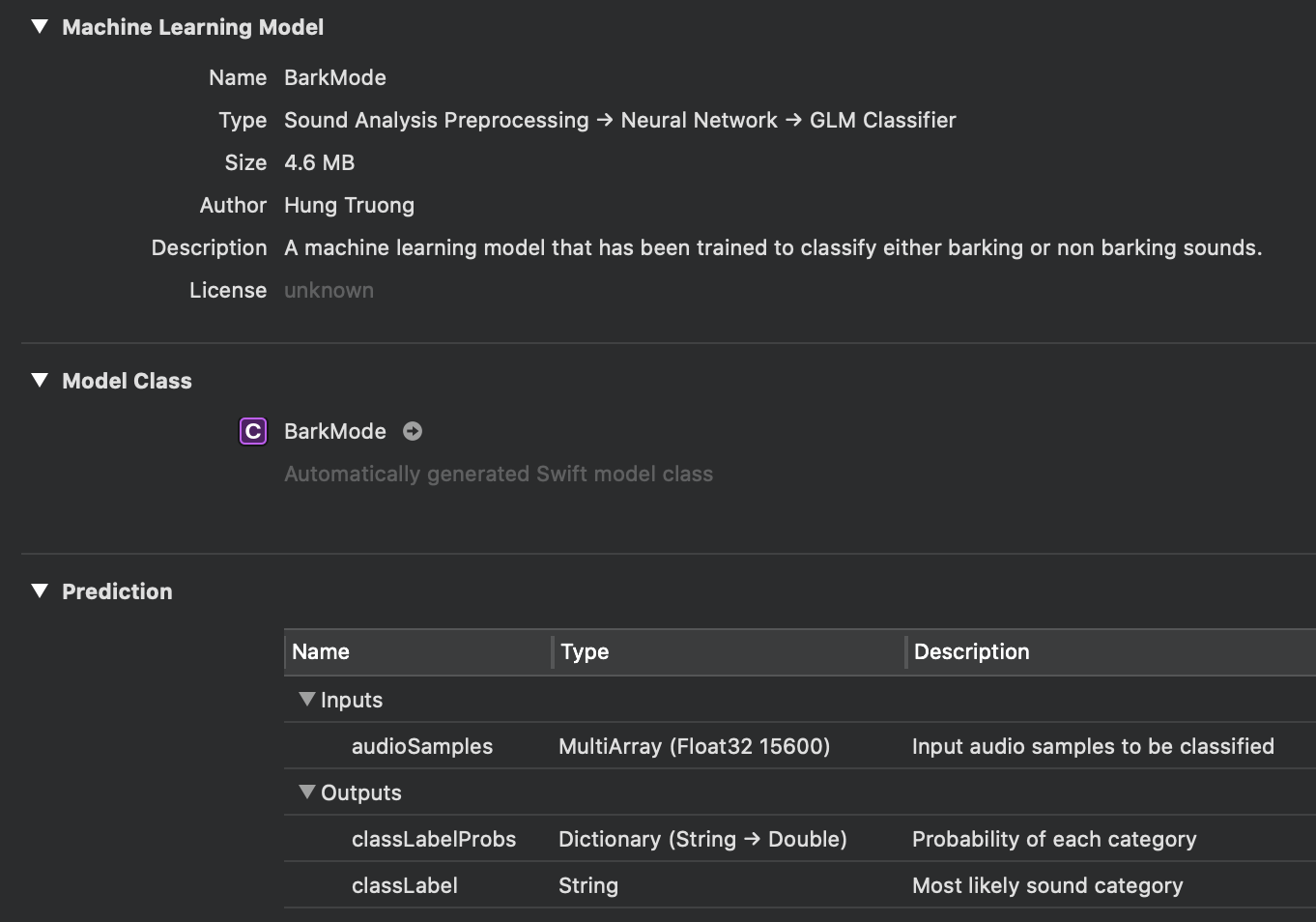
Looking at the model in Xcode, it describes an interface with an input of “audioSamples” that takes a MultiArray of (Float32 15600). I assumed this had something to do with the number of samples per second and the bitrate of the audio. I fiddled around with the AudioToolbox framework and a few other lower level audio APIs until I discovered Apple’s documentation on the SoundAnalysis framework which provides a much, much easier method of feeding audio to the model.
I implemented the steps described and extended my ViewController to conform to the SNResultsObserving protocol. Then it was a few simple steps to write some logic to handle the app detecting no barking to barking and back to no barking, and toggling the dark mode off and on.
Finally, I added a label and an image view that takes an image with different assets for the light and dark modes, which changes automatically based on the current setting.
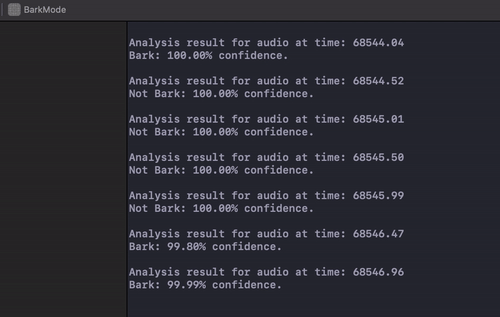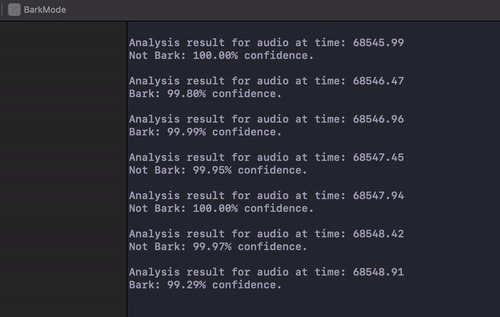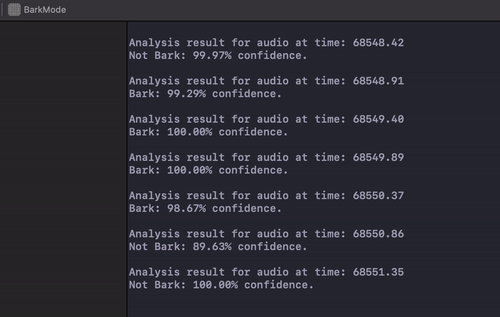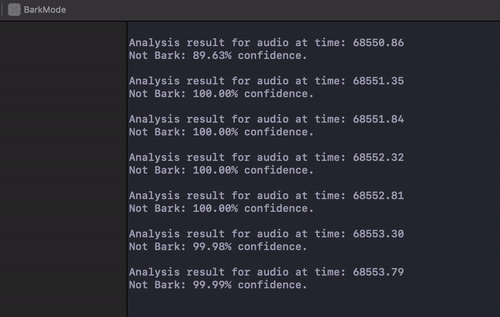
The model runs pretty quickly. Here’s a gif of the terminal output from the logging whenever some sound data comes in:
If you want to see the app in action, I created this video to demonstrate:
As it is, this app isn’t very useful for much of anything, but I could see a few potential uses for the model I trained:
- Write an app that detects your dog is unhappy when it’s at home and triggers a home automation action like playing music or shooting a treat at your dog
- Detect if suspicious sound at your house is a robber or just a dog
- Classify different types of barks and make a dog barking translation app
- For people who are allergic to dogs, advance warning of incoming dog
I’ve posted the full project to Github in case you’re curious about how I implemented the app. I didn’t upload the Create ML project but it just has a bunch of sound effect files and files of me saying gibberish. The model included in the Github repo should work fine anyway.
I’m pretty happy with my end result. It’s fun to play around with new APIs and now I can say that I’ve trained an ML model to classify sounds, in addition to implementing Dark Mode! Hopefully I’ll have some time to play with other APIs that were introduced to iOS soon.
Leave a Comment
Comments are moderated and won't appear immediately after submission.
Thank you for your comment!
Your comment has been submitted and will be published after manual approval.
Submission Error
There was an error submitting your comment. Please try again.